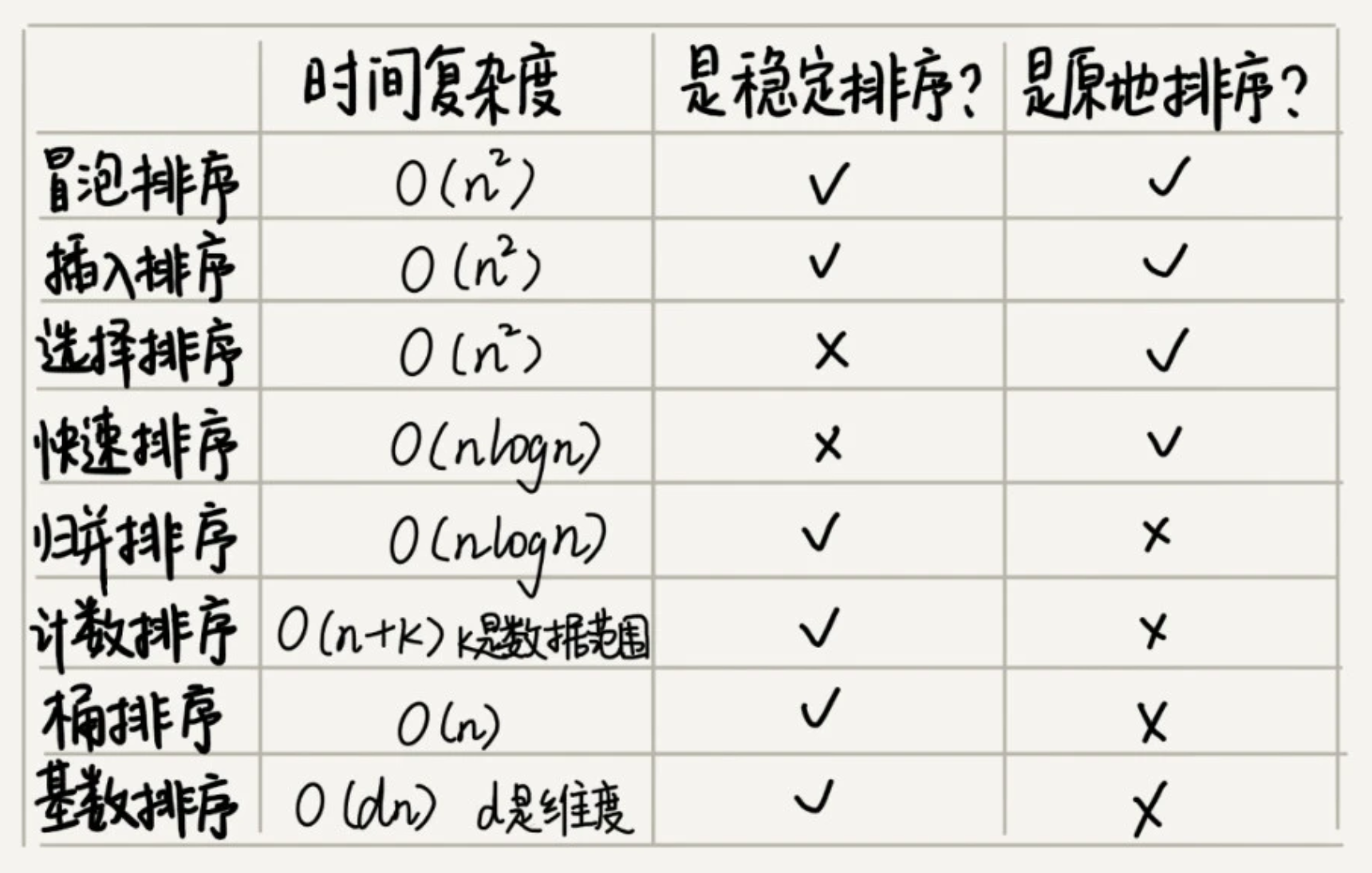
funcbubbleSort(_nums: inout [Int]) { for i in0..<nums.count-1 { var flag =true for j in0..<nums.count-1-i { if nums[j] > nums[j+1] { let temp = nums[j+1] nums[j+1] = nums[j] nums[j] = temp flag =false } } if flag { break } } }
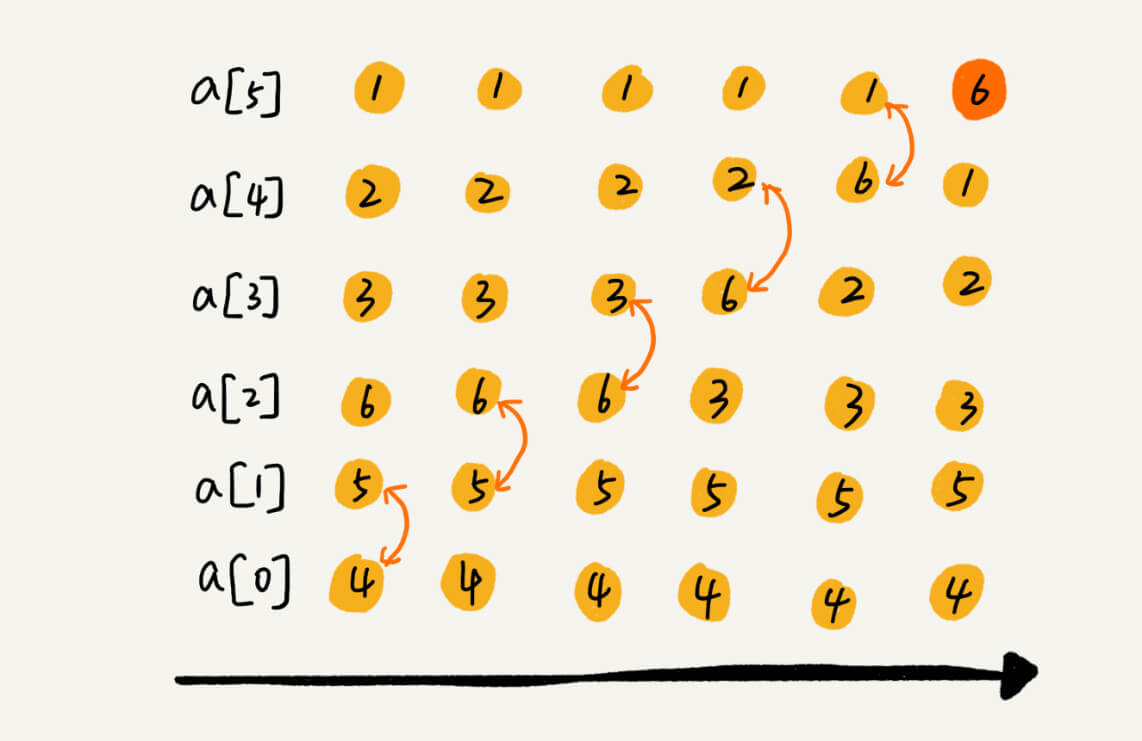
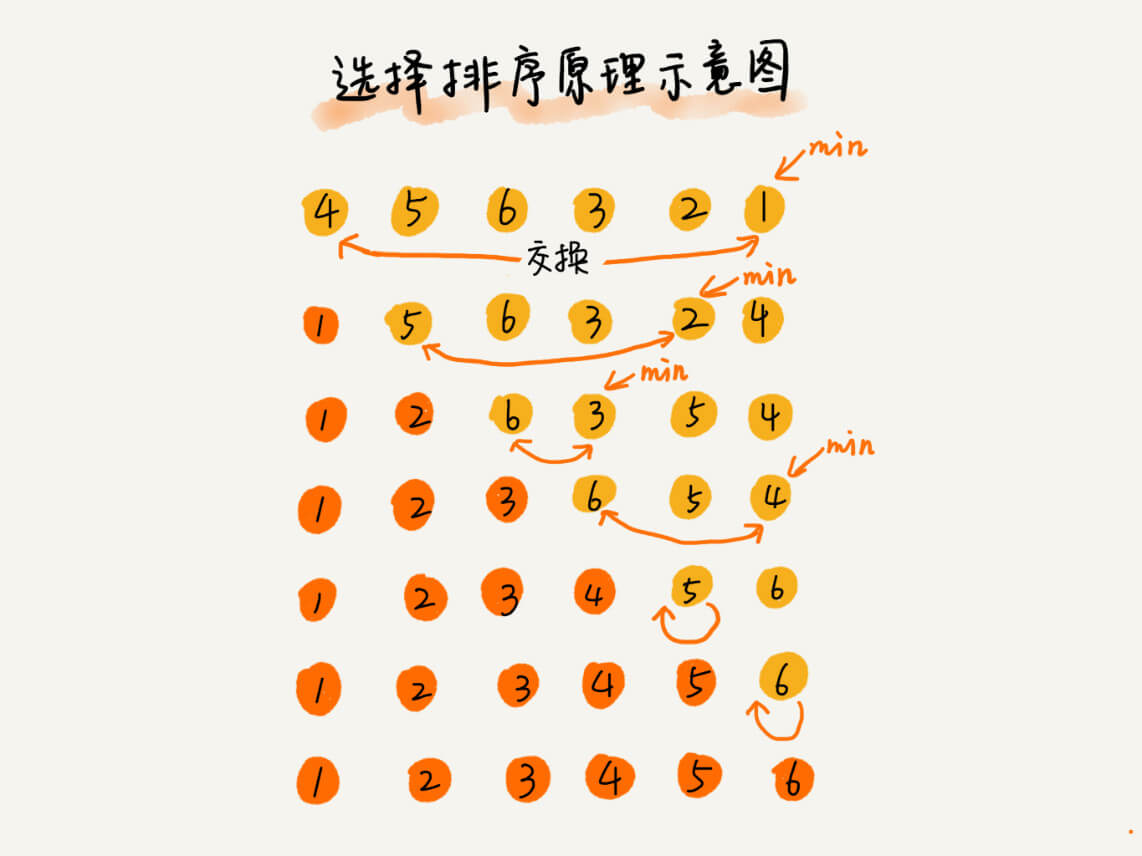
//选择排序的交换过程中破坏了稳定性,其不是稳定的排序算法 funcselectionSort(_nums: inout [Int]) { for i in0..<nums.count { var j = i var min = nums[i] var minIndex = j while j<nums.count { if nums[j]<min { min = nums[j] minIndex = j } j +=1 } let temp = nums[i] nums[i] = min nums[minIndex] = temp } }
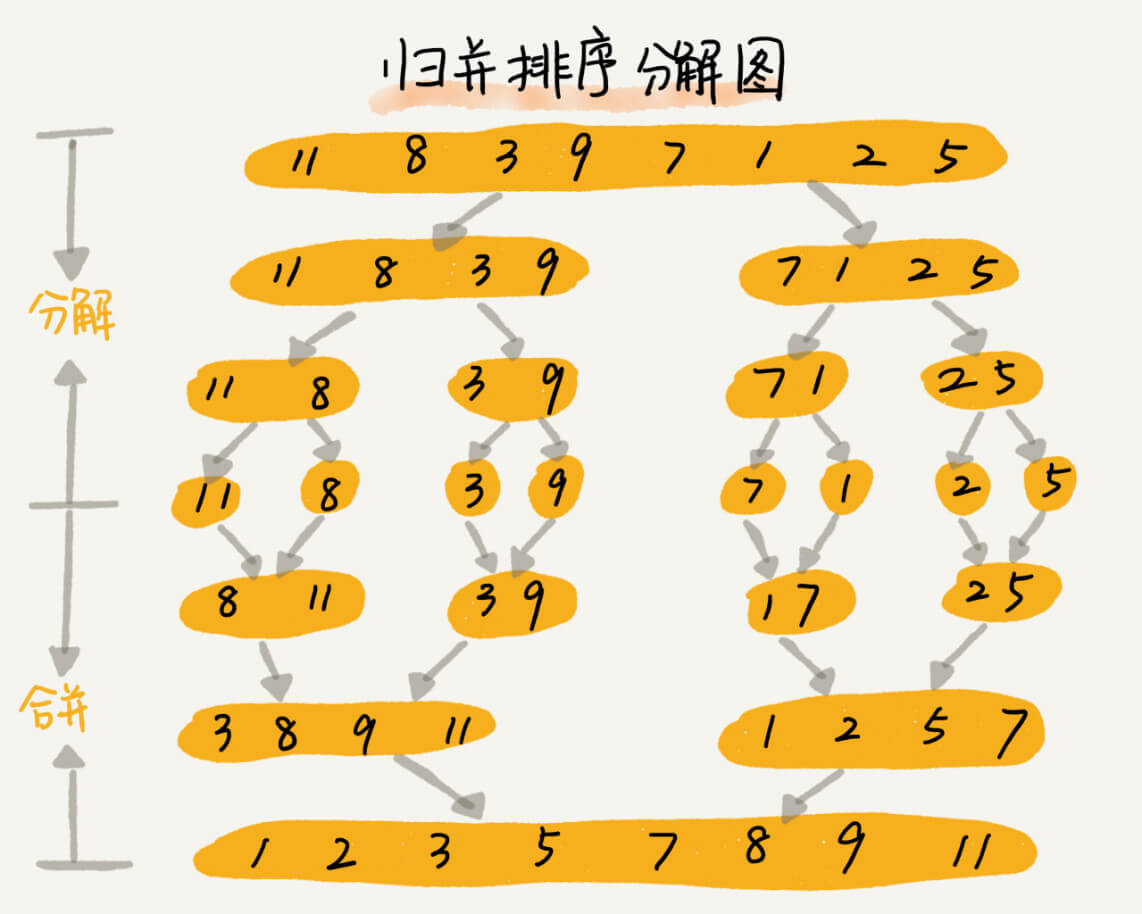
需要用到一个数组保存排序结果,也就是合并的时候,需要开辟空间来存储排序结果,在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
时间复杂度
最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
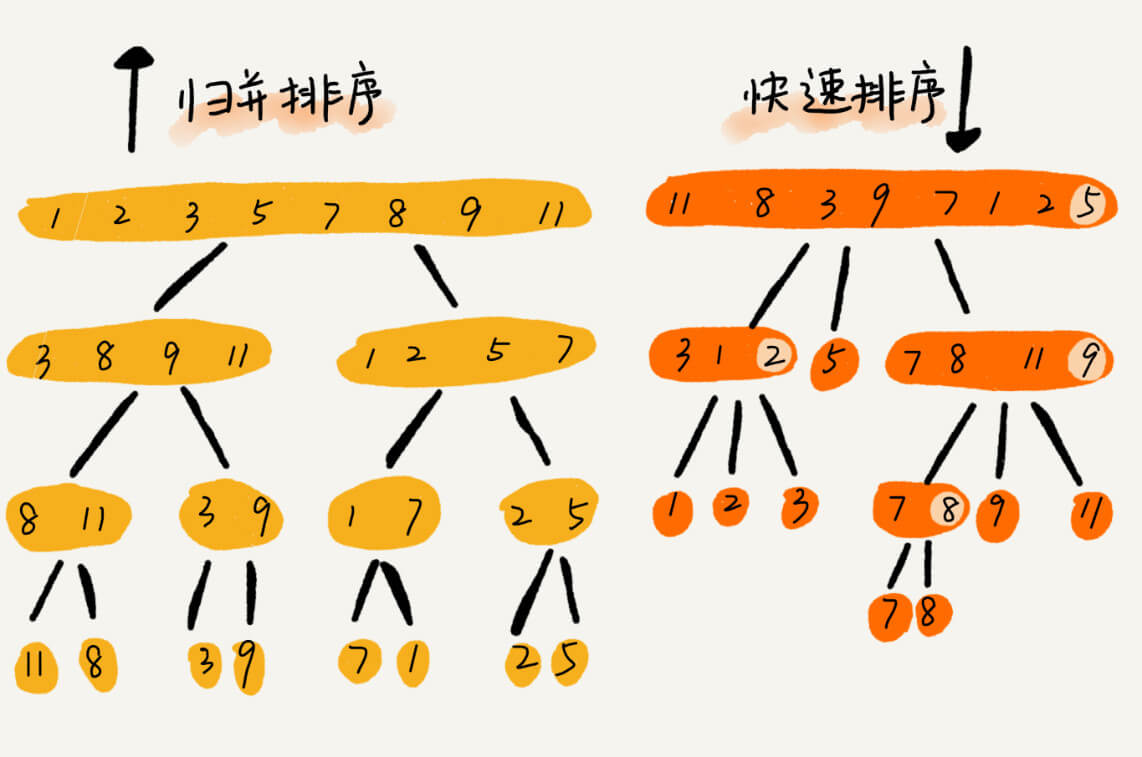
快速排序
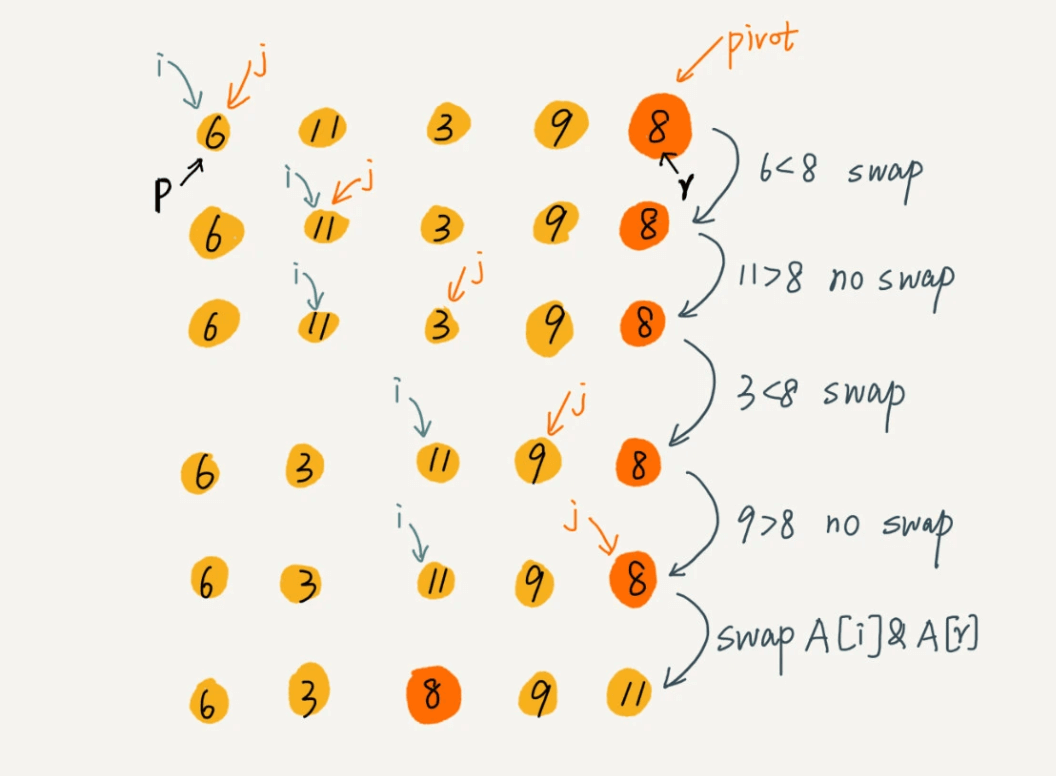
要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
funcpartition(_array:inout [Int],_low:Int,_high:Int) -> Int { let pivot = array[high]//直接选择最后一个数字为分区点 var i = low for j in low..<high { if array[j] < pivot { let temp = array[j] array[j] = array[i] array[i] = temp i +=1 } } array[high] = array[i] array[i] = pivot return i }
funcquickSortC(_array:inout [Int],_low:Int,_high:Int) -> Void { if low >= high { return } let index = partition(&array, low, high) quickSortC(&array,low,index-1) quickSortC(&array,index+1,high) } funcquickSort(_array:inout [Int]){ quickSortC(&array, 0, array.count-1) }
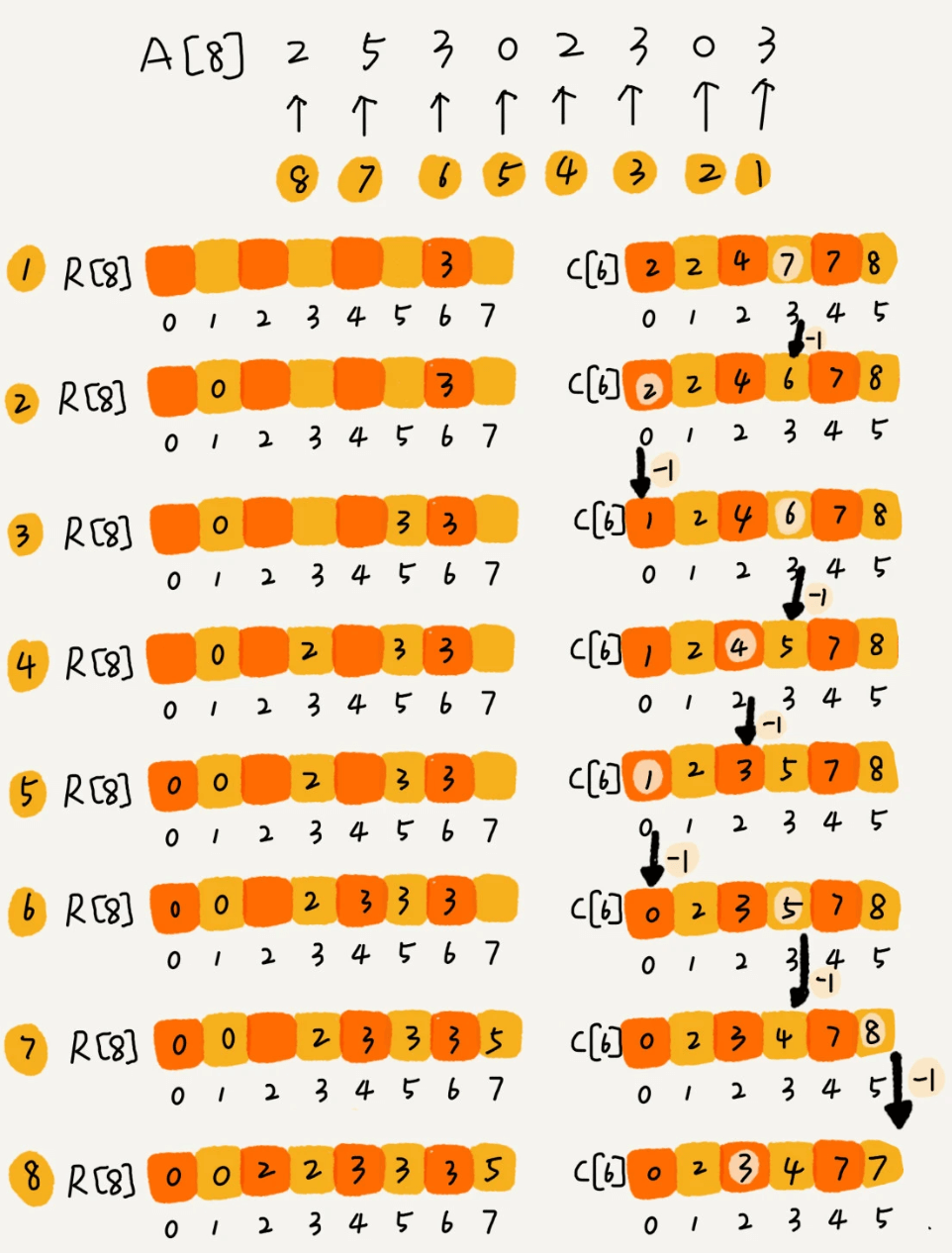
let max = array.max() ??0 var countArray = [Int](repeating: 0, count: Int(max +1)) //其中存储小于或者等于元素值的个数 for i in array { countArray[i] +=1//计算每个元素出现的次数 }
for i in1..< countArray.count { let sum = countArray[i] + countArray[i -1] countArray[i] = sum//算出小于等于此元素值的个数 } var sortedArray = [Int](repeating: 0, count: array.count) for i in array { countArray[i] -=1 sortedArray[countArray[i]] = i } return sortedArray }
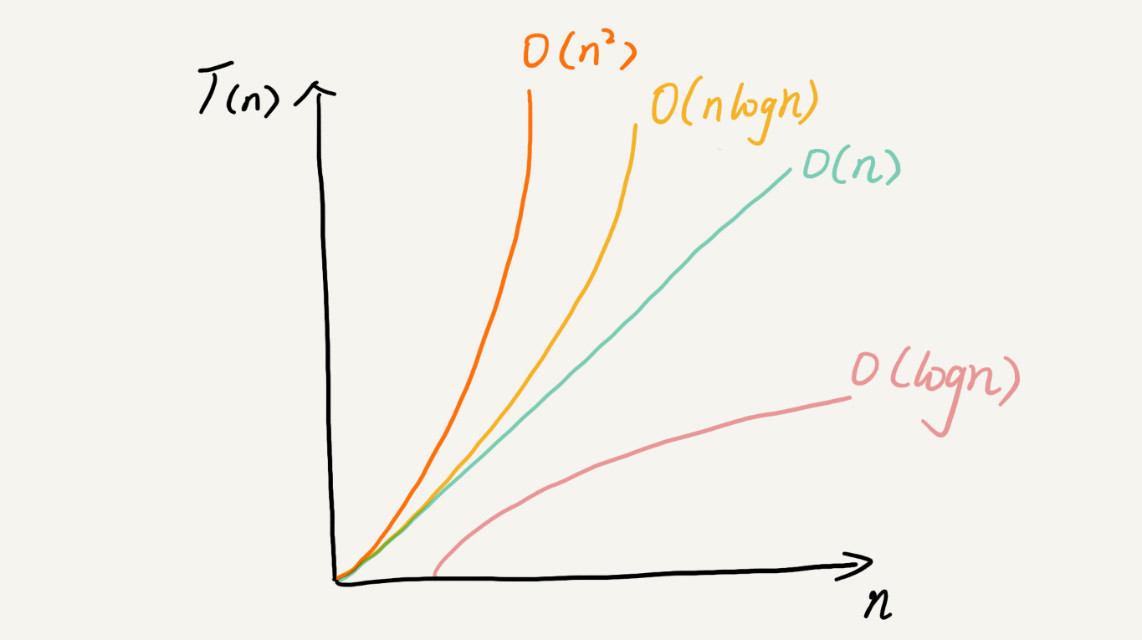
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是代表代码执行时间随数据规模增长的变化趋势,所以也叫渐进时间复杂度。 当 n 很大时,f(n)中的低阶,常量,系数并不左右增长趋势,所以可以忽略,只记录一个最大量级就可以了。例如:T(n)=O(n²),T(n)=O(logn)这样。常见的时间复杂度有如下几种:
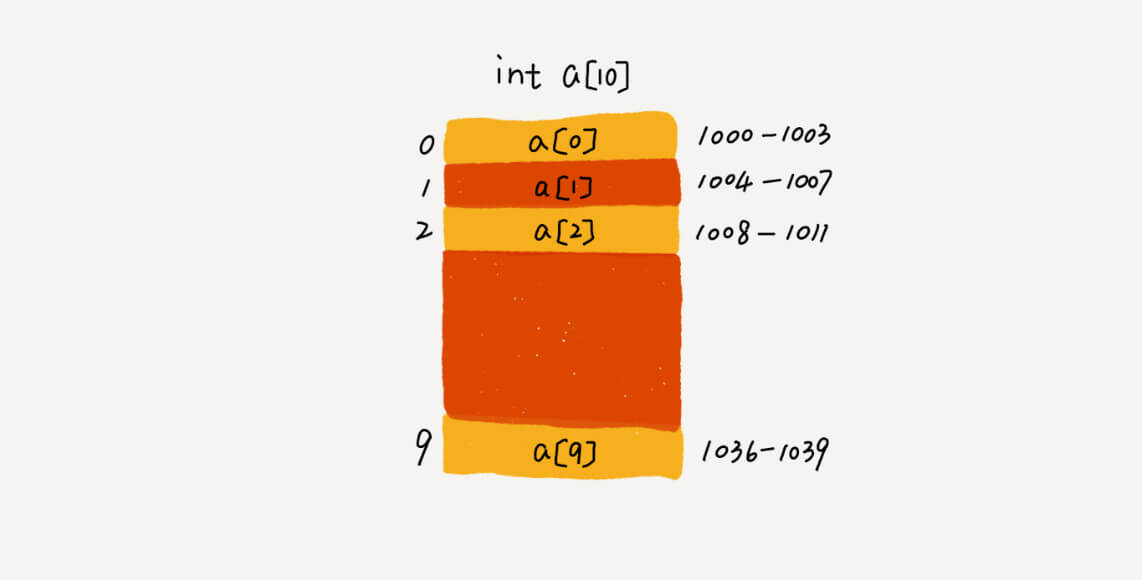
//按下标随机访问数组中某个元素时,通过如下寻址公式,计算出该元素的内存地址 a[i]_address = base_address + i * data_type_size
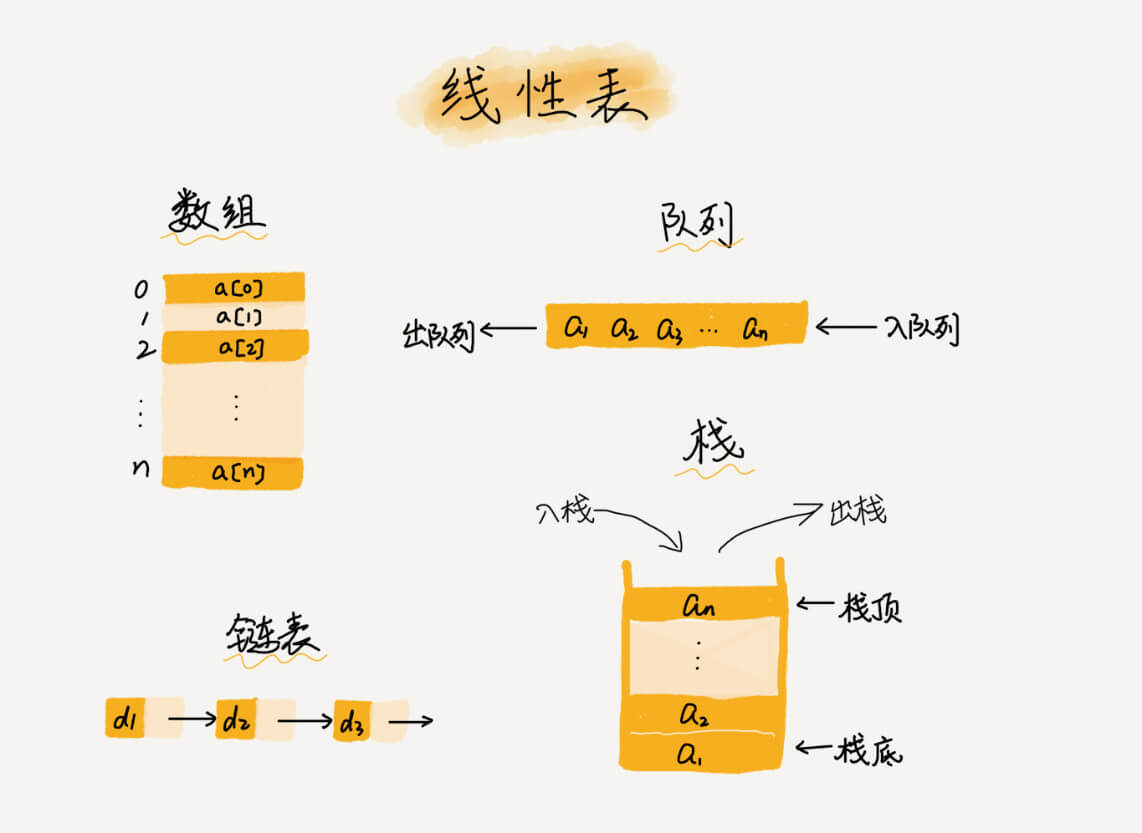
插入操作:将一个数据插入到长度为 n 的数组的第 k 个位置,需要先将 k~n 的这部分元素顺序向后挪一位,再插入新元素。其最好、最坏及平均时间复杂度为 O(1)、O(n)、O(n)。但是当数组中的数据没有任何规律,只是被当做存储数据的集合时,可以直接将第 k 位数据搬到数组的最后,将新元素直接放到第 k 位,将时间复杂度减为 O(1)。
Dispatch Queue 是管理你添加的要执行任务的队列,它按照先进先出(FIFO)的顺序执行处理。Dispatch Queue 是线程安全的,也就意味着你可以同时在多个线程访问它。Dispatch Queue 分为 Serial Queue和 Concurrent Queue 两种(注:下面部分图片来自 Ray 家的教程):
串行队列(Serial Queue)
Serial Queue 保证在任何时间同时只能执行一个任务,它会等待当前正在进行的任务结束之后再处理其他任务。由 GCD 来控制任务的执行时机,两个任务之间会有多久的间隔也是不确定的。一旦生成 Serial Queue 并添加了任务进去,系统对于一个 Serial Queue 就只生成并使用一个线程。但是多个 Serial Queue 对应各自不同的线程,因此他们之间是可以并行执行的。Serial Queue 与线程的关系可以看下面的gif图(注:图片截取自 WWDC 视频):
Main Queue 中的任务是在主线程 Runloop 中执行的,因为主线程只有一个,Main Queue 自然也就是一个 Serial Queue。由于在主线程中执行,因此要将用户界面的更新等必须在主线程中执行的任务添加到 Main Queue 中。可以通过dispatch_get_main_queue()函数获取。
Global Queue 是整个系统共享的 Concurrent Queue,它包含四个不同优先级的队列:high, default, low, 和 background。在 iOS 8.0 之前,只需要将任务提交到对应执行优先级的 Global Queue 中即可保证任务执行的优先级顺序。例如获取一个高优先级队列的函数如下:
1 2
//第二个参数 flag 是为未来保留的,现在传入 0 即可。 dispatch_queue_t highGlobalQue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0);
现在你不需要直接指定 Queue 的优先级了,而是指定一个 Quality of Service (QoS) 级别来暗示任务的重要性,然后 GCD 通过这个值来决定使用哪个优先级的队列。Qos 级别有以下几种:
上面代码创建的 Serial Queue,在往这个队列中提交了任务之后,系统就会为它生成一个线程。使用这个方法创建多少个 Serial Queue,就会对应生成多少个相互间并行的线程,因此如果创建大量的 Serial Queue 就会消耗大量内存,引起大量上下文切换,使得程序性能降低因此只应该在多个线程更新共享资源会导致数据竞争时,使用一个 Serial Queue.
Dispatch Group 涉及到集合的同步化,你将多个任务添加到一个分组之后,就可以等待所有的任务执行完毕,或者提供一个回调函数后继续往下执行,当所有任务执行完毕后收到通知,执行回调函数。更厉害的是你提交的任务可以属于不同的 Queue。这种特性常用于必须在指定的任务都完成的情况下才能继续的情况。
我们先通过dispatch_group_create方法生成一个 group, 然后通过dispatch_group_async函数将 block 添加进 queue 中并与 group 联系起来之后,group 就会保持一个其中未完成任务的数量值,连接一个任务时增加该值,任务完成后减少该值。后面的dispatch_group_wait和dispatch_group_notify函数就是使用这个数量值来判断与这个 group 连接起来的所有任务是否完成。
dispatch_group_async函数与dispatch_async相似,只是多了将任务 block 与 group 联系起来的作用。
在这里我们使用了dispatch_group_wait函数,它会一直处于调用状态而不返回,从而阻塞了当前线程,直到 group 中的所有任务执行完成或者到达指定的时间。返回时若所有任务都执行完成,这个函数的返回值为 0,否则不为 0。你也可以指定时间参数为DISPATCH_TIME_FOREVER让它一直等待直到全部任务完成。
这样就能达到我们的目的了。dispatch_group_enter函数表示一个任务进入这个 group 了,会增加队列中未完成任务的数量值,dispatch_group_leave表示一个任务已经完成,会减少队列中未完成任务的数量值。这两个函数的组合使得我们可以更合理的控制 group 中未完成任务的个数,从而达到更精确的控制。dispatch_group_enter与dispatch_group_leave应该彼此对应,如果 enter 了而没有 leave,那么这一组任务将永远不会完成。
isa_tnewisa(0); //这里截取SUPPORT_INDEXED_ISA = 0 时的代码,查知只有在watchABI的环境下SUPPORT_INDEXED_ISA值才为1 newisa.bits = ISA_MAGIC_VALUE; // isa.magic is part of ISA_MAGIC_VALUE // isa.nonpointer is part of ISA_MAGIC_VALUE newisa.has_cxx_dtor = hasCxxDtor; newisa.shiftcls = (uintptr_t)cls >> 3;
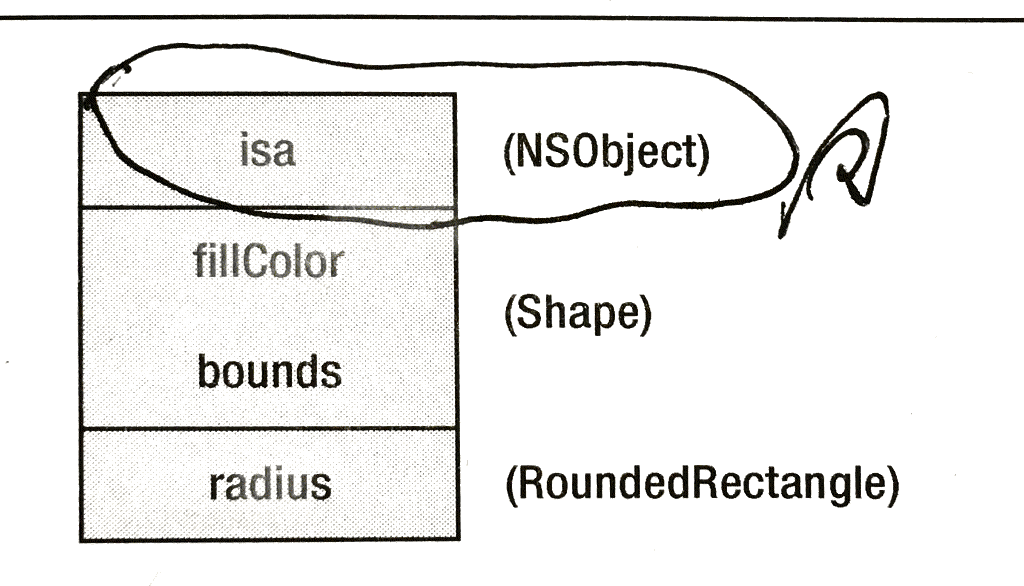
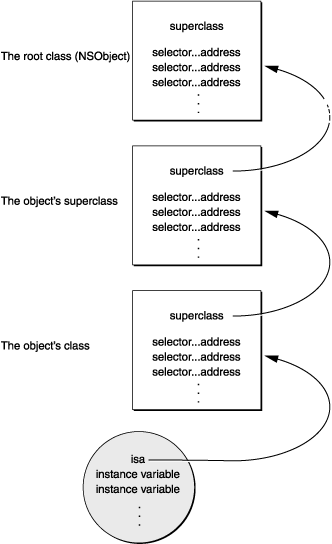
可以看出这个结构体中只有一个 64 位的值bits,该数据中保存了一个指向class_rw_t结构体的指针和是否为 swift 类、是否有默认的retain/release等方法及是否要求 raw isa 三个标志位。结构体中还提供了使用掩码来访问这些数据的方法(甚至还提供一些对class_rw_t结构体中flags字段的访问函数)。引用深入解析 ObjC 中方法的结构文章中的配图可以看得更明白一些:
This function may only be called after objc_allocateClassPair and before objc_registerClassPair. Adding an instance variable to an existing class is not supported.
//将 ro 替换为 rw,标记类为 已实现|实现中 ro = (constclass_ro_t *)cls->data(); if (ro->flags & RO_FUTURE) { // This was a future class. rw data is already allocated. rw = cls->data(); ro = cls->data()->ro; cls->changeInfo(RW_REALIZED|RW_REALIZING, RW_FUTURE); } else { // Normal class. Allocate writeable class data. rw = (class_rw_t *)calloc(sizeof(class_rw_t), 1); rw->ro = ro; rw->flags = RW_REALIZED|RW_REALIZING; cls->setData(rw); } //查询是否为元类 isMeta = ro->flags & RO_META; //设置version rw->version = isMeta ? 7 : 0; // old runtime went up to 6
// Choose an index for this class. // Sets cls->instancesRequireRawIsa if indexes no more indexes are available cls->chooseClassArrayIndex(); //仅在watchABI下有效
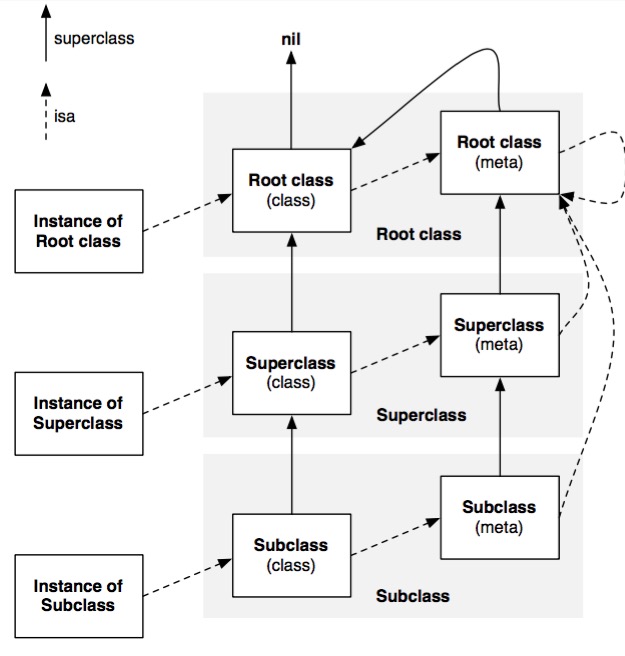
// Realize superclass and metaclass, if they aren't already. // This needs to be done after RW_REALIZED is set above, for root classes. // This needs to be done after class index is chosen, for root metaclasses. supercls = realizeClass(remapClass(cls->superclass)); metacls = realizeClass(remapClass(cls->ISA()));
//...省略SUPPORT_NONPOINTER_ISA时的代码
// Update superclass and metaclass in case of remapping cls->superclass = supercls; cls->initClassIsa(metacls);
// Reconcile instance variable offsets / layout. // This may reallocate class_ro_t, updating our ro variable. if (supercls && !isMeta) reconcileInstanceVariables(cls, supercls, ro);
// Set fastInstanceSize if it wasn't set already. cls->setInstanceSize(ro->instanceSize);
// Copy some flags from ro to rw if (ro->flags & RO_HAS_CXX_STRUCTORS) { cls->setHasCxxDtor(); if (! (ro->flags & RO_HAS_CXX_DTOR_ONLY)) { cls->setHasCxxCtor(); } }
// Connect this class to its superclass's subclass lists if (supercls) { addSubclass(supercls, cls); } else { addRootClass(cls); }
classref_t *classlist = _getObjc2NonlazyClassList(mhdr, &count); for (i = 0; i < count; i++) { schedule_class_load(remapClass(classlist[i])); }
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count); for (i = 0; i < count; i++) { category_t *cat = categorylist[i]; Class cls = remapClass(cat->cls); if (!cls) continue; // category for ignored weak-linked class realizeClass(cls); assert(cls->ISA()->isRealized()); add_category_to_loadable_list(cat); }
当你编译包含 Objective-C 类和方法的代码时,编译器会创建实现该语言动态特征的数据结构和函数调用。数据结构中会包含类和分类的定义以及协议声明中的信息。其中有《The Objective-C Programming Language》中Defining a Class and Protocols章节中讨论过的类和协议对象,以及方法选择器,实例变量模板及其他从源代码中提取出的信息。最基本的运行时方法是在Messaging中描述的发送消息的方法。它通过源代码中的消息表达式调用。
在 Cocoa 环境中,动态加载普遍被用于应用程序的自定义化。运行时加载其他人编写的模块-诸如 Interface Builer 加载自定义的选项板, OS X 系统偏好设置加载自定义的偏好模块。这些可加载模块可以通过一种你允许的但却不能参与或者定义它的方式来扩展你应用的能力。你只需要提供框架,由其他人来实现代码。(注:本段原文中似乎是以系统为第一人称来表述动态加载的功能,不清楚时可翻看原文)。
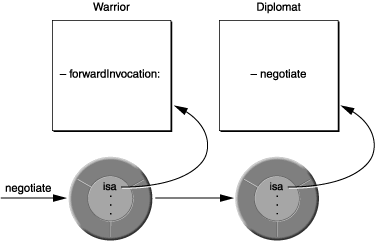
- (BOOL)respondsToSelector:(SEL)aSelector { if ( [super respondsToSelector:aSelector] ) returnYES; else { /* Here, test whether the aSelector message can * * be forwarded to another object and whether that * * object can respond to it. Return YES if it can. */ } returnNO; }
为协助运行时系统,编译器会将每个方法中的返回值和参数的类型编码成字符串并且和方法选择器联系起来。这种编码方案在其他上下文中也很有用所以通过@encode()编译器指令将其公开化了。给一个特定类型,@encode()会返回一个编码了这个类型的字符串。类型可以是int,指针,有标签的结构体或联合这样的基础类型,或者一个类名,或者任何类型。这个指令可以像 C 中的sizeof()操作符一样用。
当编译器碰到属性声明时(在 The Objective-C Programming Language 的 Declared Properties 章节描述),会生成与封装它的类、分类或者协议相关的描述性的元数据。你可以使用能够通过名字在类或协议中查询属性的函数,获取属性的类型作为一个@encode字符串的函数或者可以拷贝属性特征列表为一个 C 字符串数组的函数来访问这些元数据。每一个类和协议都有一串的已声明的属性可以使用。
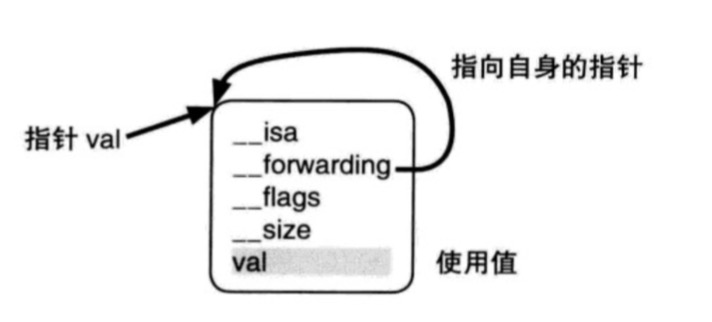
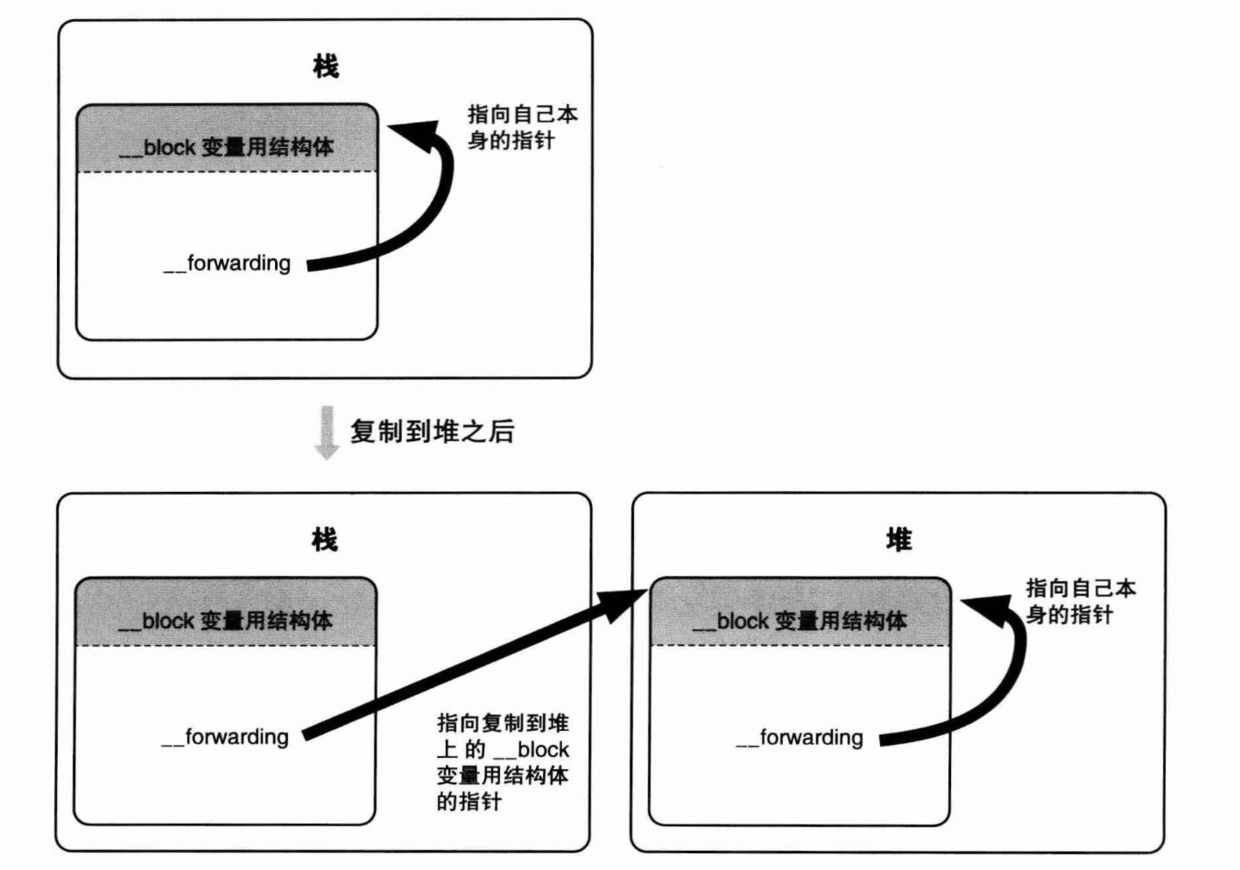
struct__Block_byref_val_0 {//被捕获的__block变量生成的结构体并不在Block用__main_block_impl_0结构体中,这样做是为了能再多个Block中使用同一个__block变量 void *__isa; __Block_byref_val_0 *__forwarding; int __flags; int __size; int val;//最初的自动变量变为了结构体中的实例变量 };










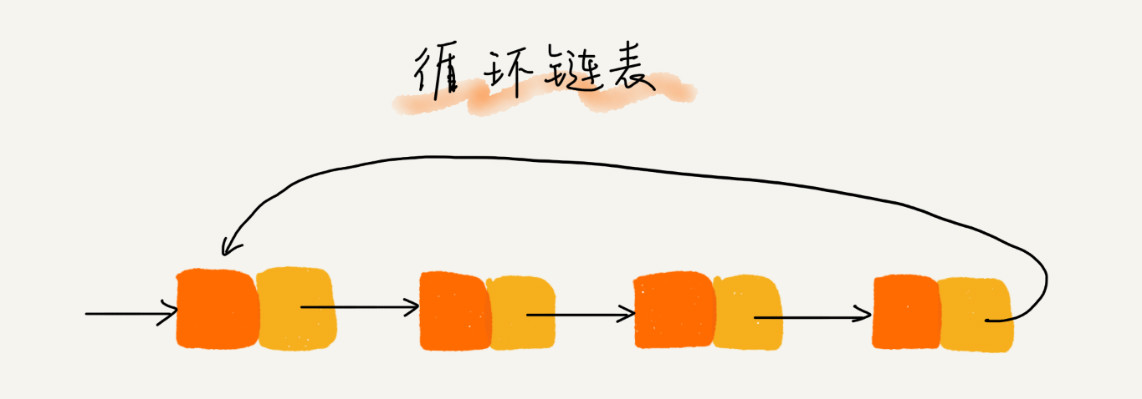
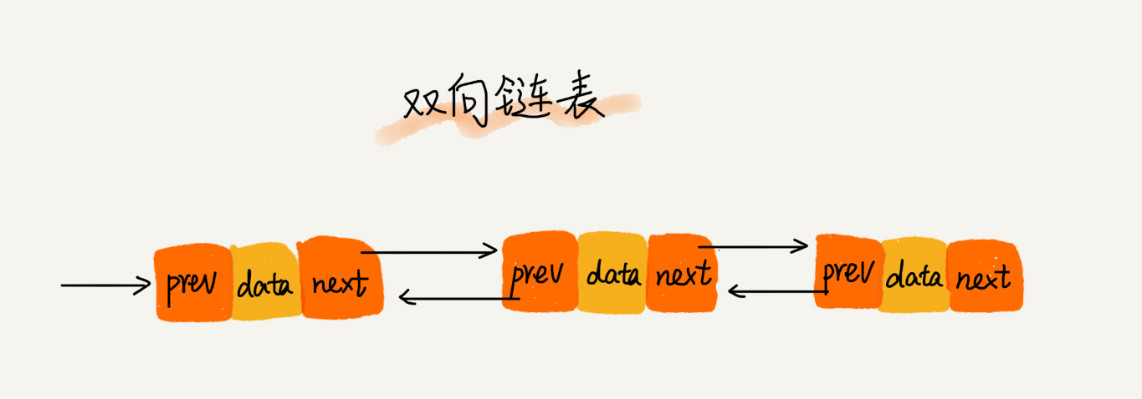
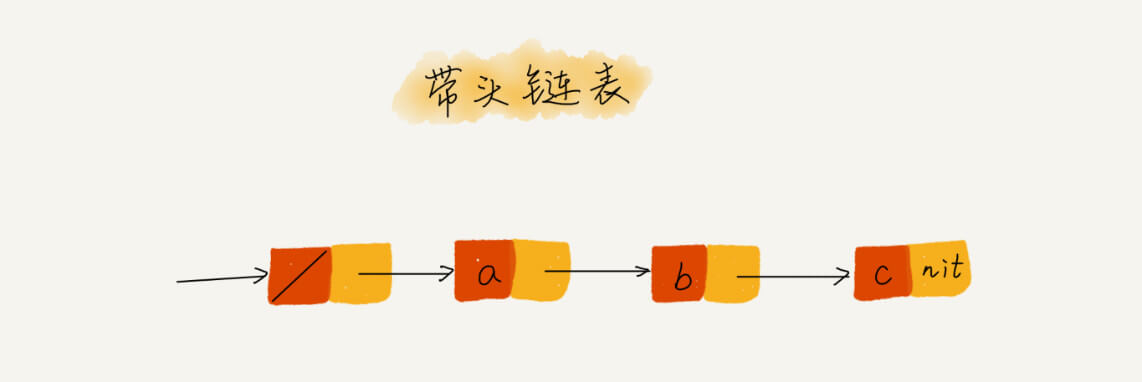
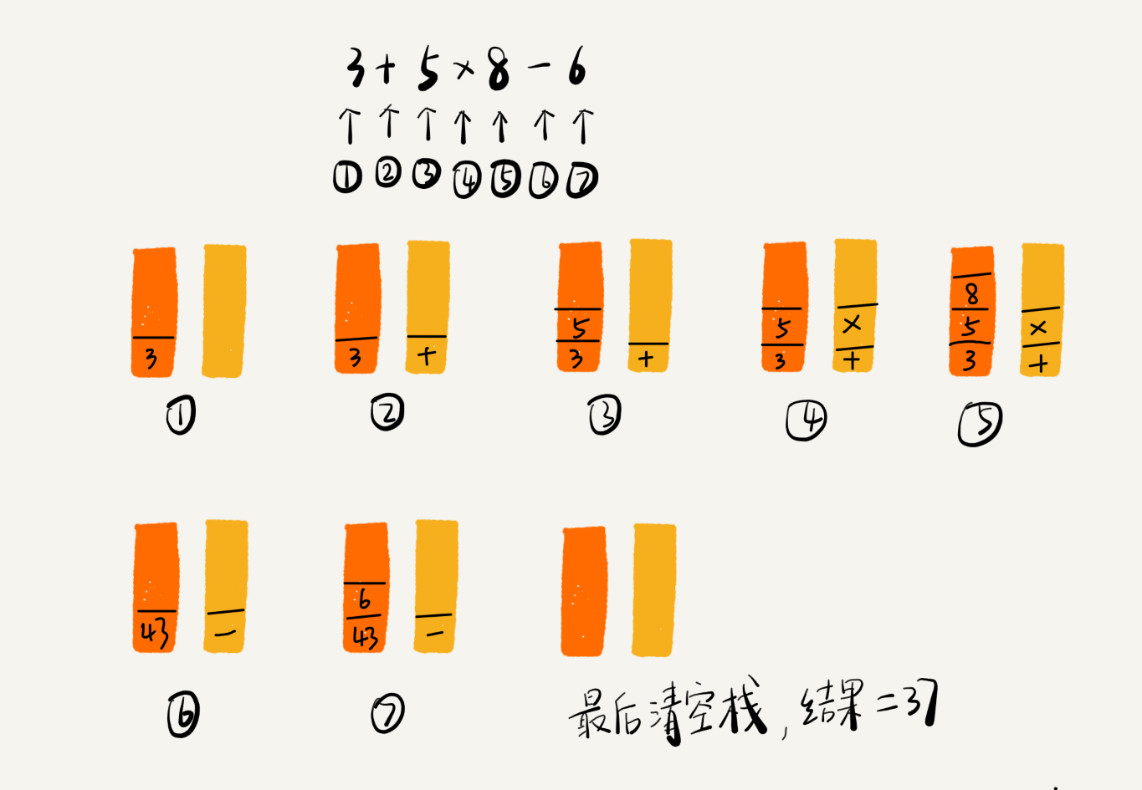
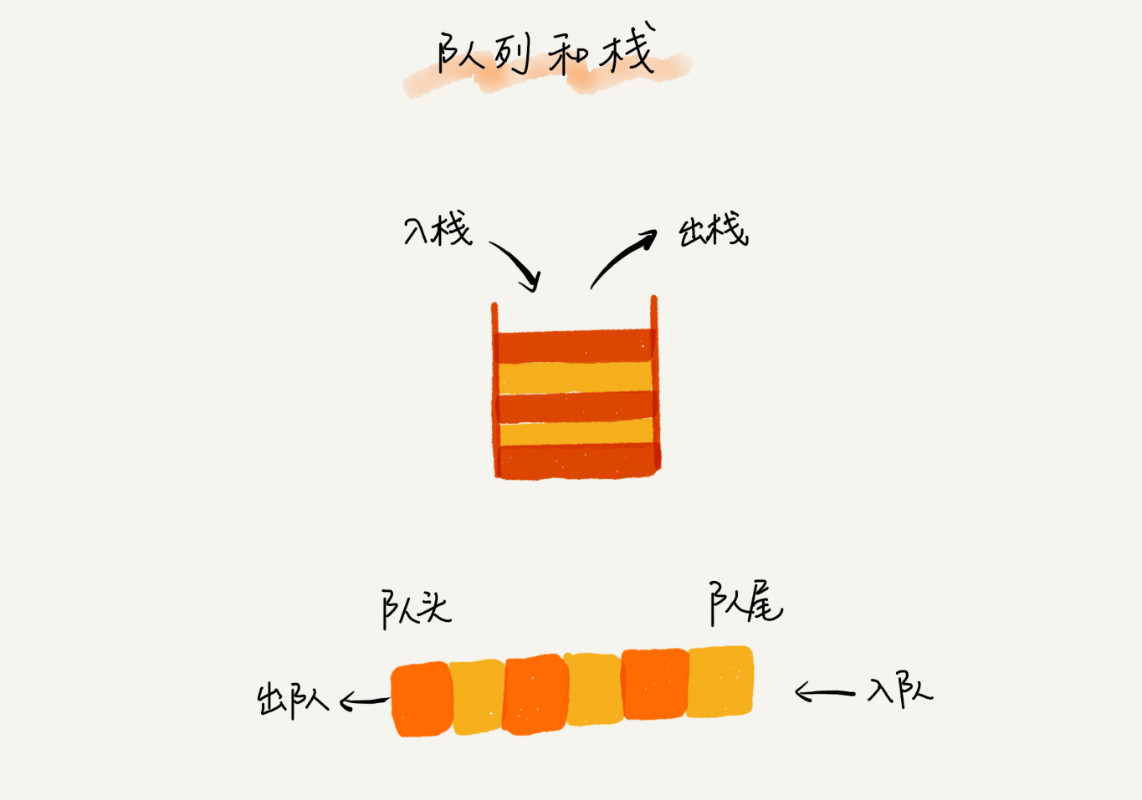
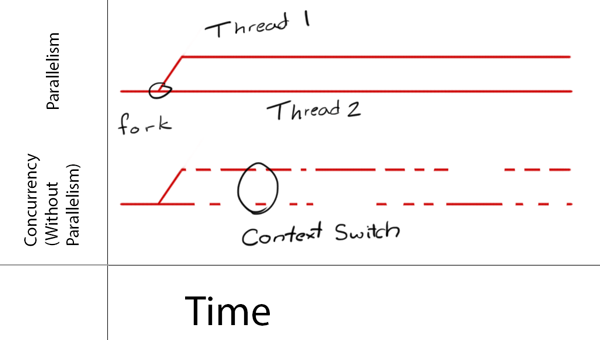
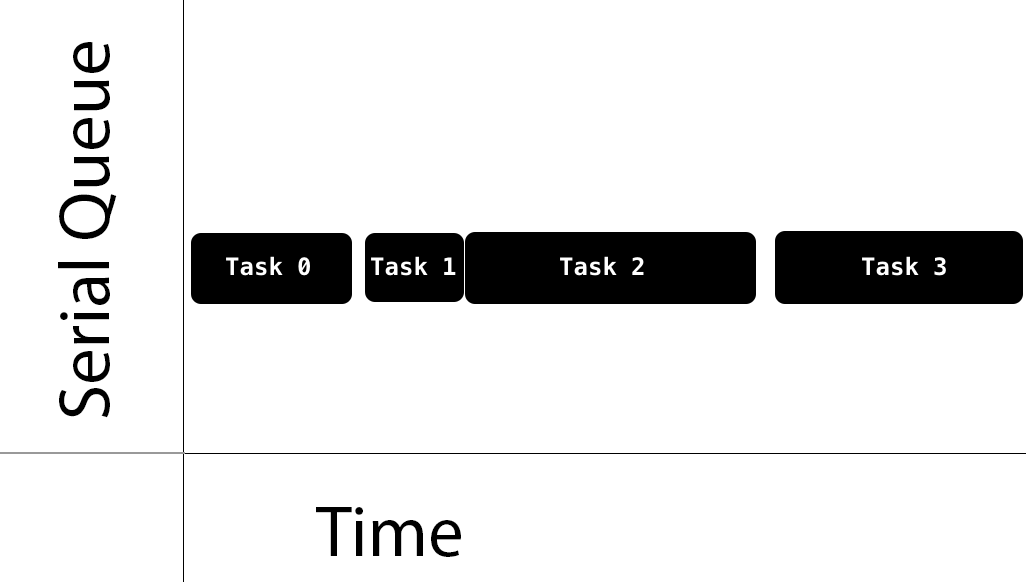
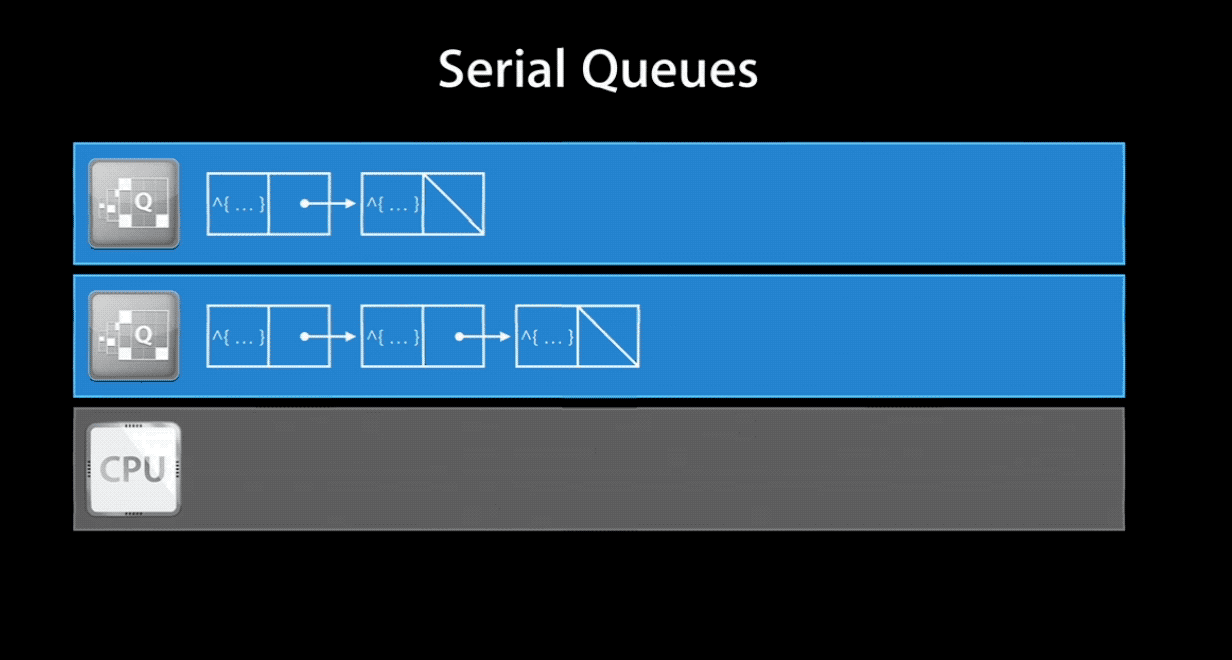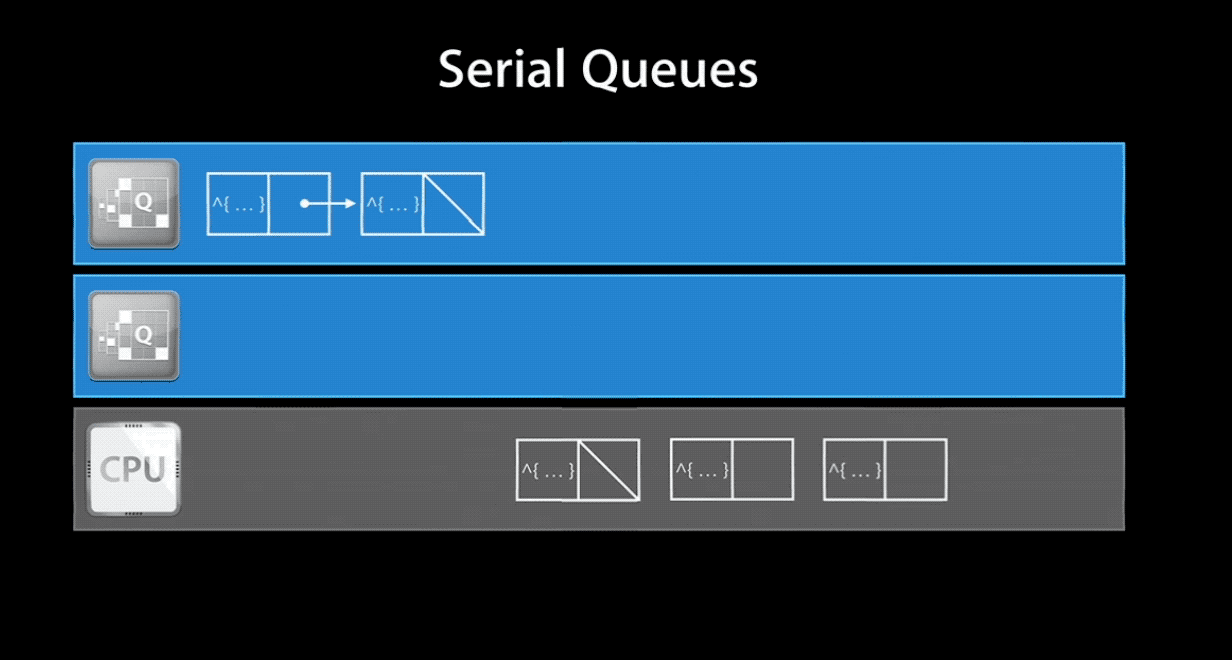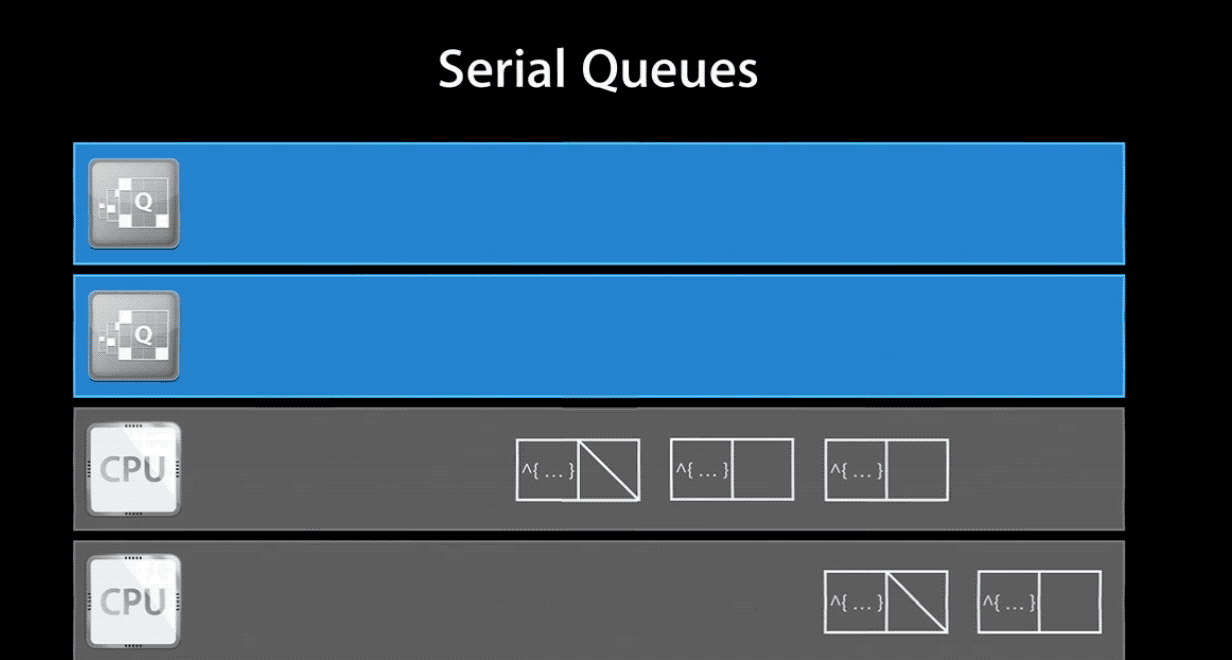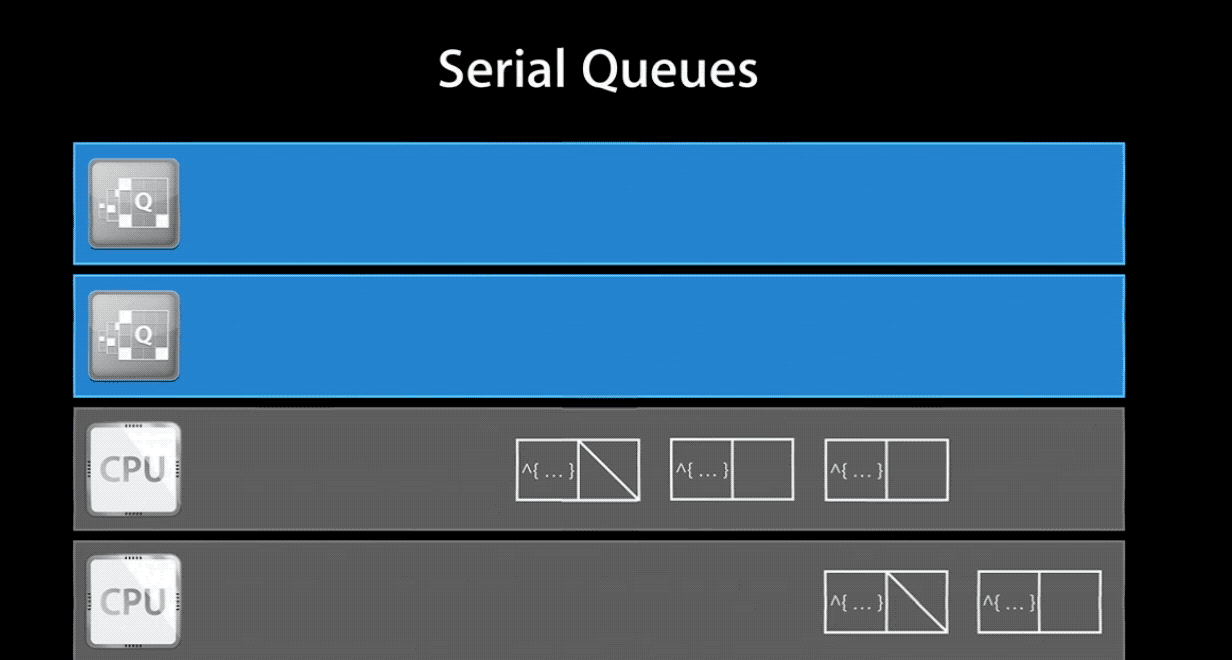
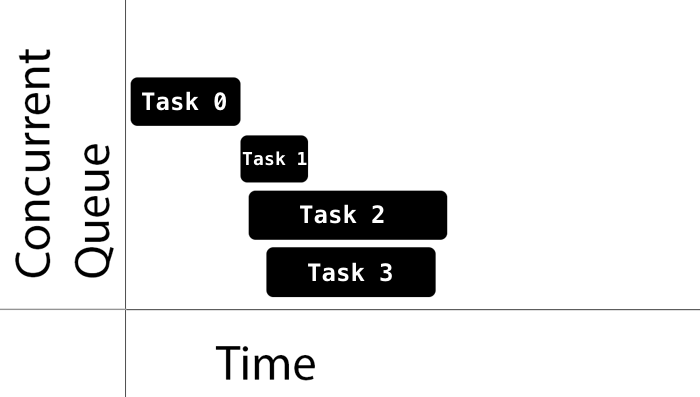
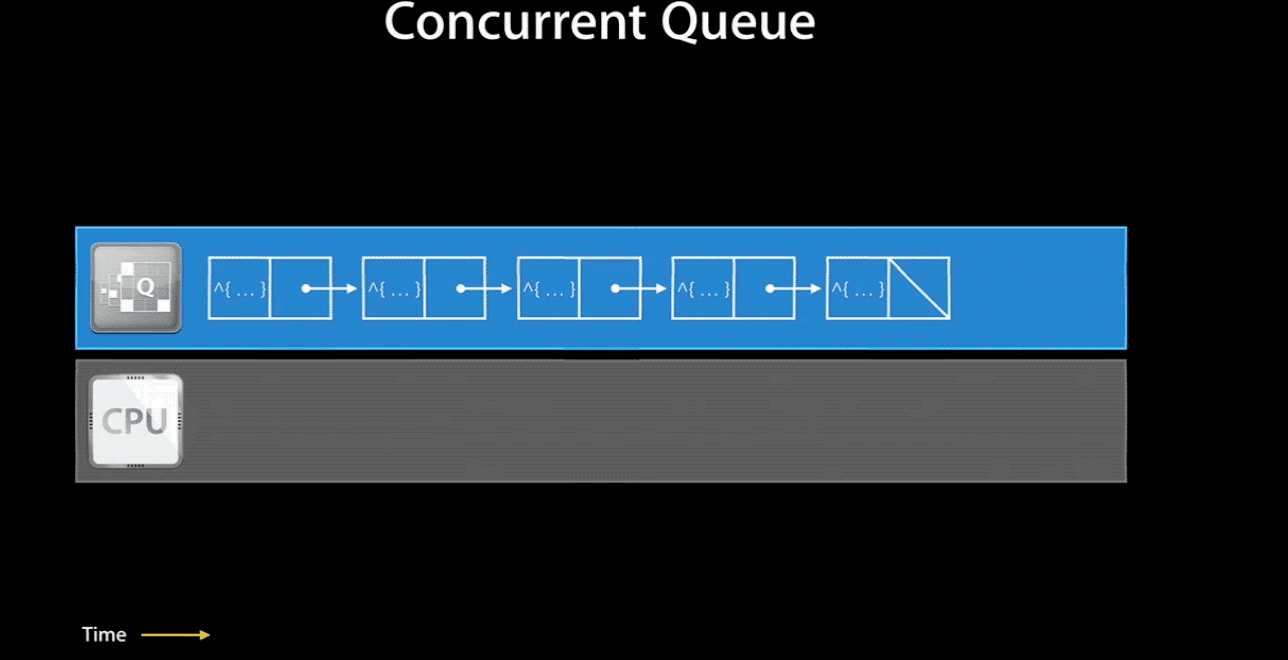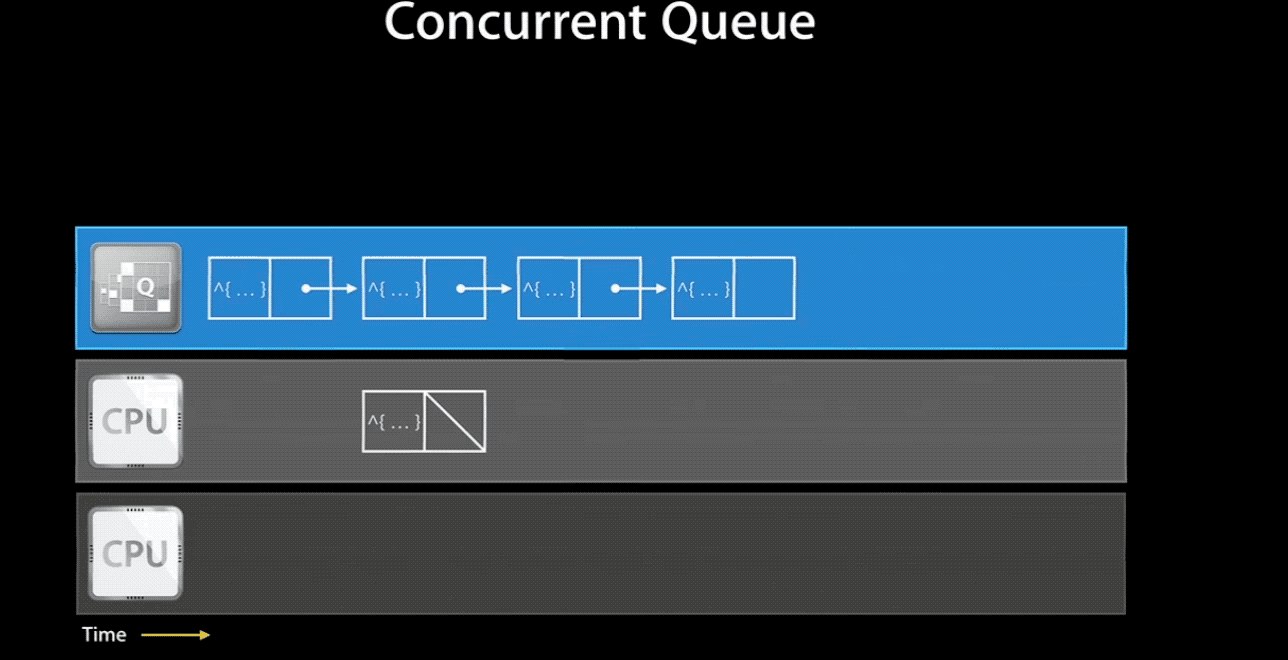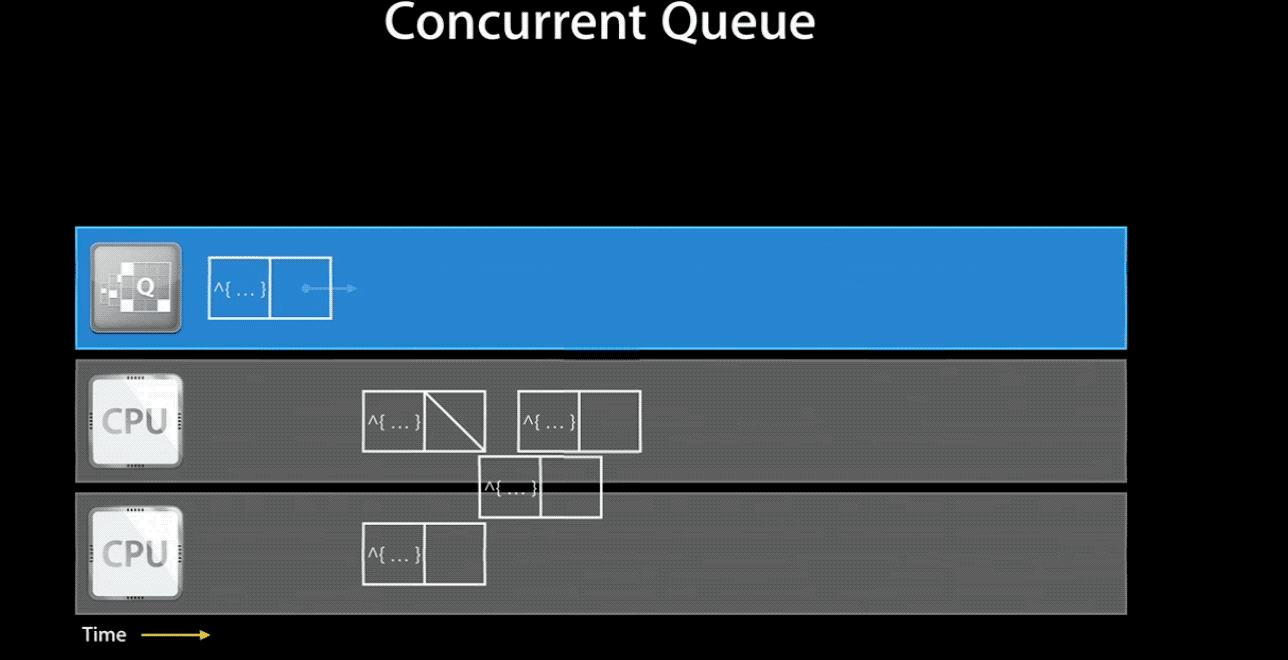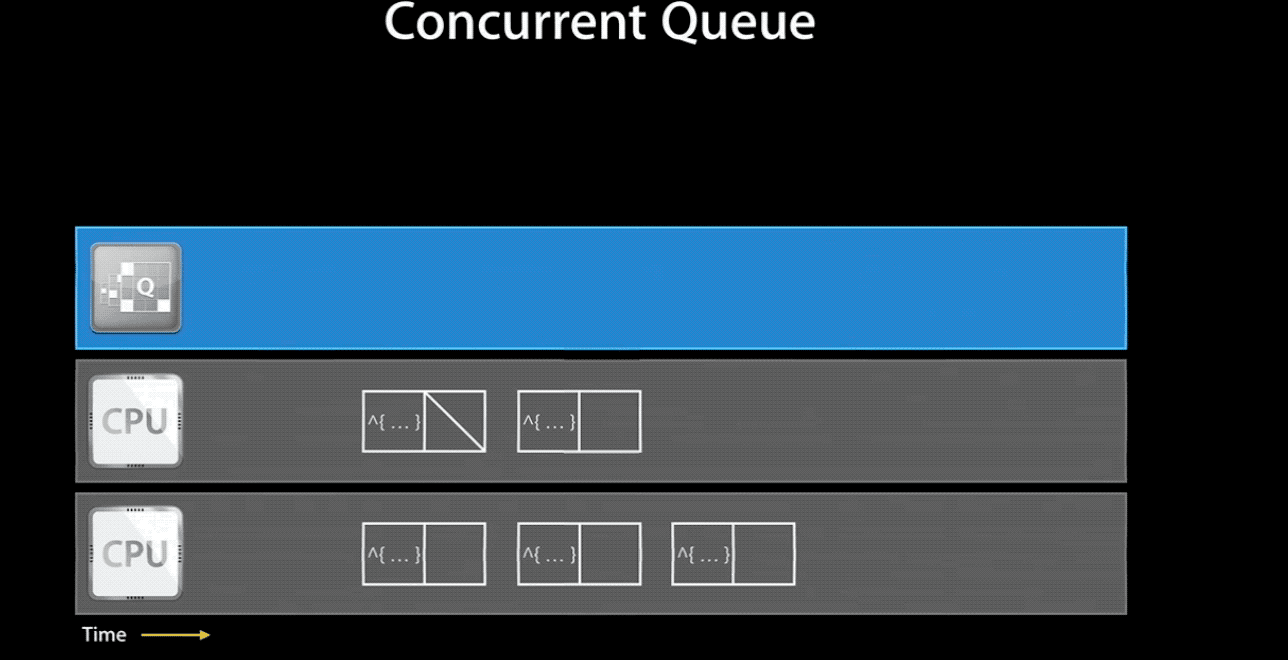
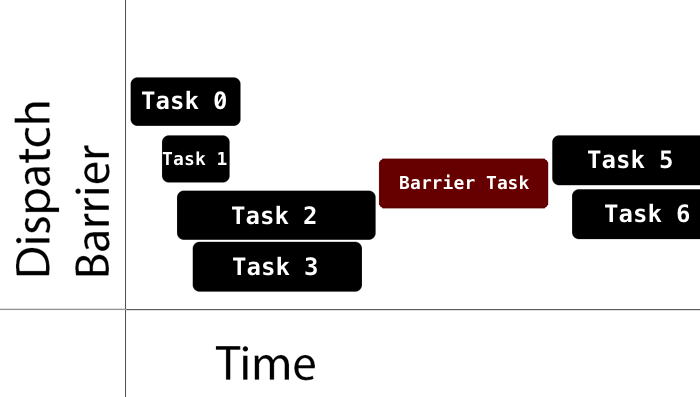
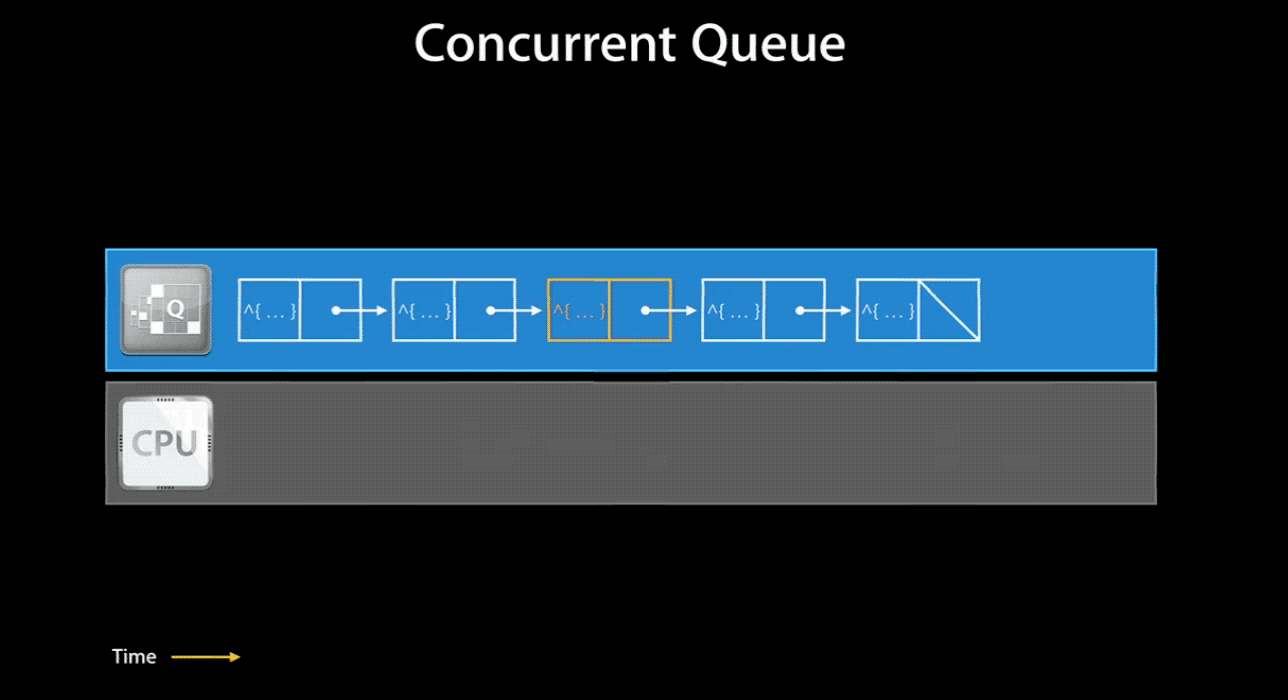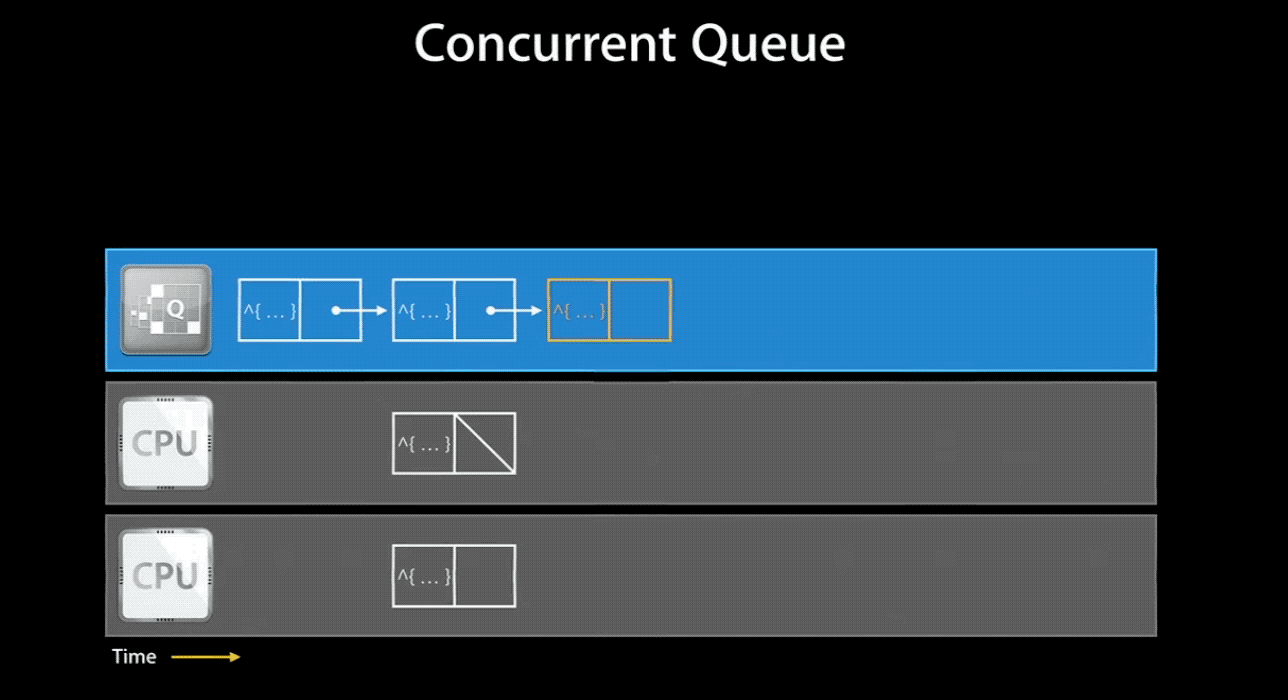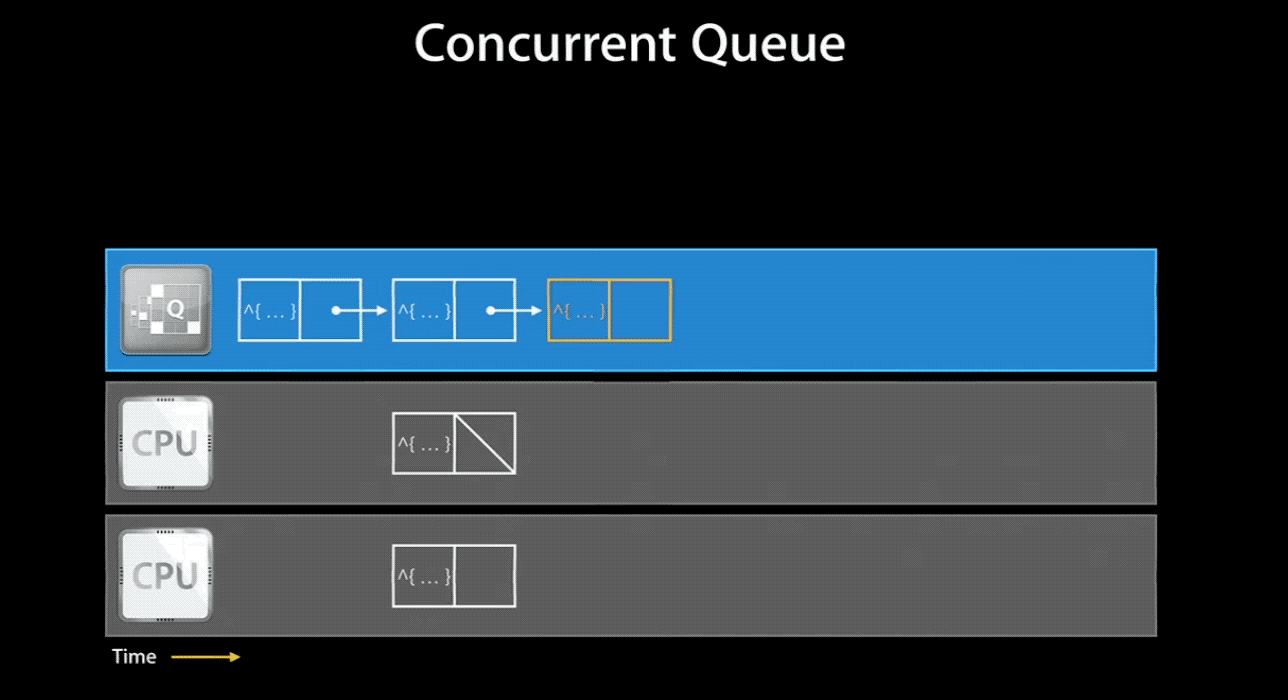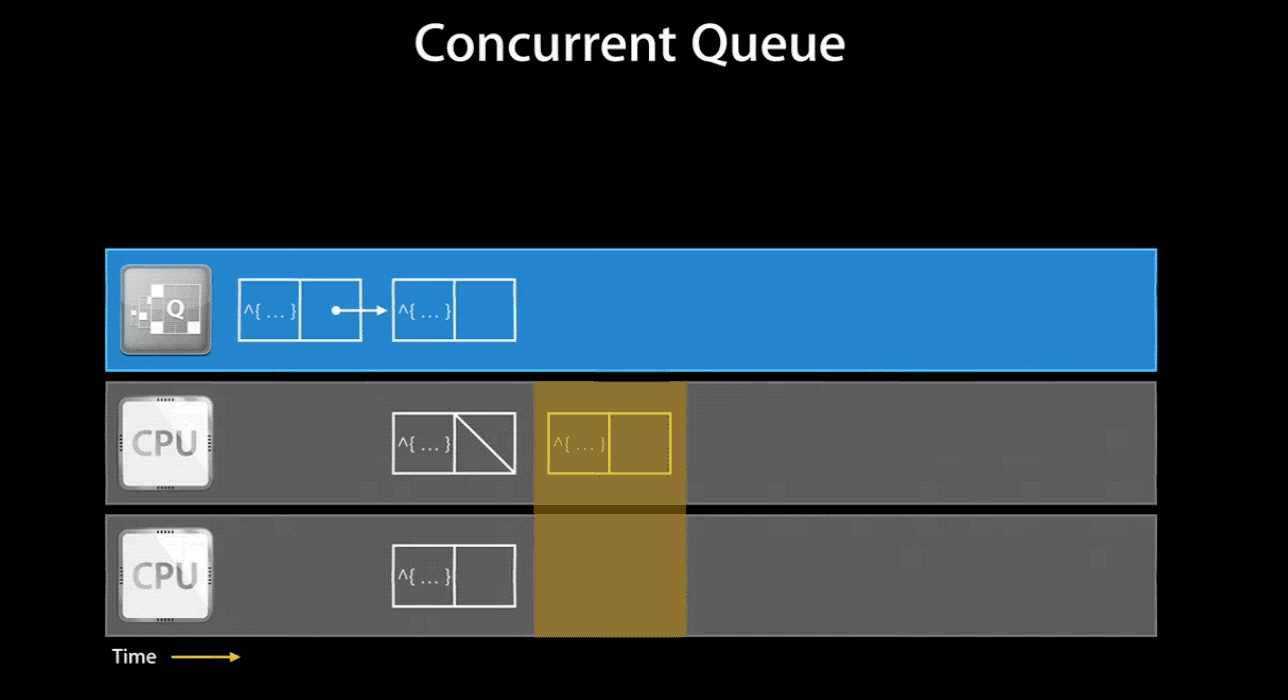
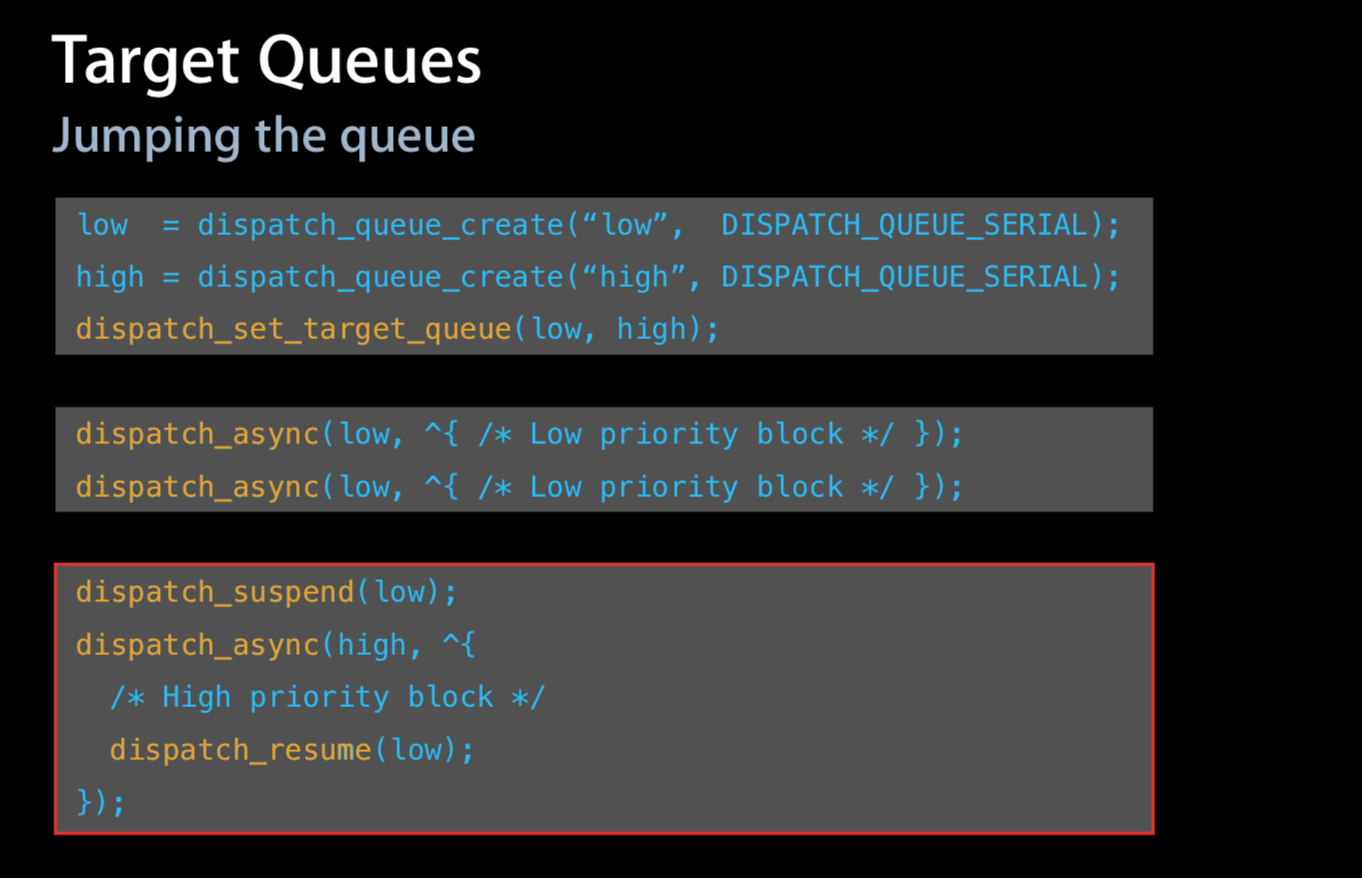
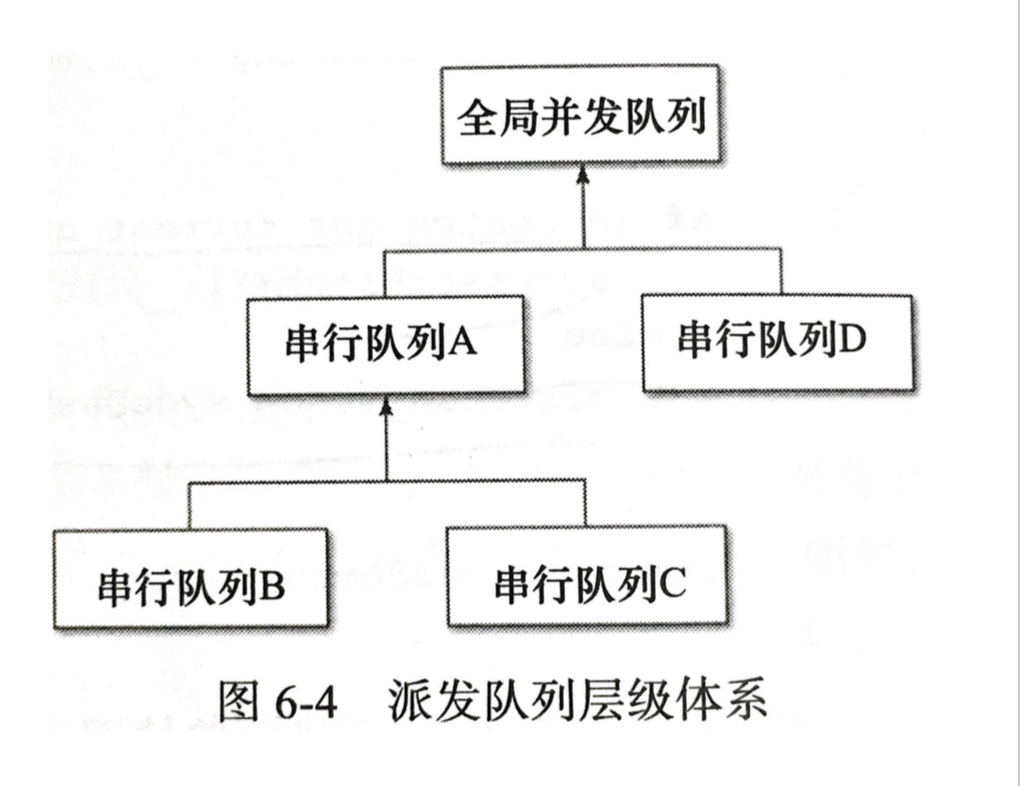 当然,如果你将一个 concurrent queue 的 target queue 指向 serial queue,那么其中的任务会串行的执行。
当然,如果你将一个 concurrent queue 的 target queue 指向 serial queue,那么其中的任务会串行的执行。